graph BT;
A(User)
B(Project Library)
C(virtualenv)
D(R Installation)
E(System Libraries)
F(Python Installation)
G[Operating System]
B-->A
C-->A
D-->B
E-->B
E-->C
F-->C
G-->D
G-->E
G-->F
Reproducible Environments
Manage environments for data science.
Great data science work should be reproducible. Being able to repeat experiments is the foundation of all science. Reproducing work is also critical for business applications: scheduled reporting, team collaboration, project validation.
The purpose of this site is to help you understand the key use cases for reproducible environments, the strategies you can use to create them, and the tools you’ll need to master.
While everyone should have a plan for reproducible environments, here are a few signs to suggest environment management has gone wrong:
- Code that used to run no longer runs, even though the code has not changed.
- You are afraid to upgrade or install a new package, because it might break your code or someone else’s.
- Typing
install.packagesin your environment doesn’t do anything, or doesn’t do the right thing.
If you’re an individual data scientist, there are two things you should do before you continue any further with environment management: learn about RStudio Projects and use version control.
If you prefer videos to reading, checkout this webinar.
Use Cases
Environment management takes work. Here are some cases where the reward is worth the effort:
- When you are working on a long-term project, and need to safely upgrade packages.
- In cases where you and your team need to collaborate on the same project, using a common source of truth.
- If you need to validate and control the packages you’re using.
- When you are ready to deploy a data product to production, such as a Shiny app, R Markdown document, or plumber API.
Strategies
Use cases provide the “why” for reproducible environments, but not the “how”. There are a variety of strategies for creating reproducible environments. It is important to recognize that not everyone needs the same approach to reproducibility. If you’re a student reporting an error to your professor, capturing your sessionInfo() may be all you need. In contrast, a statistician working on a clinical trial will need a robust framework for recreating their environment. Reproducibility is not binary!
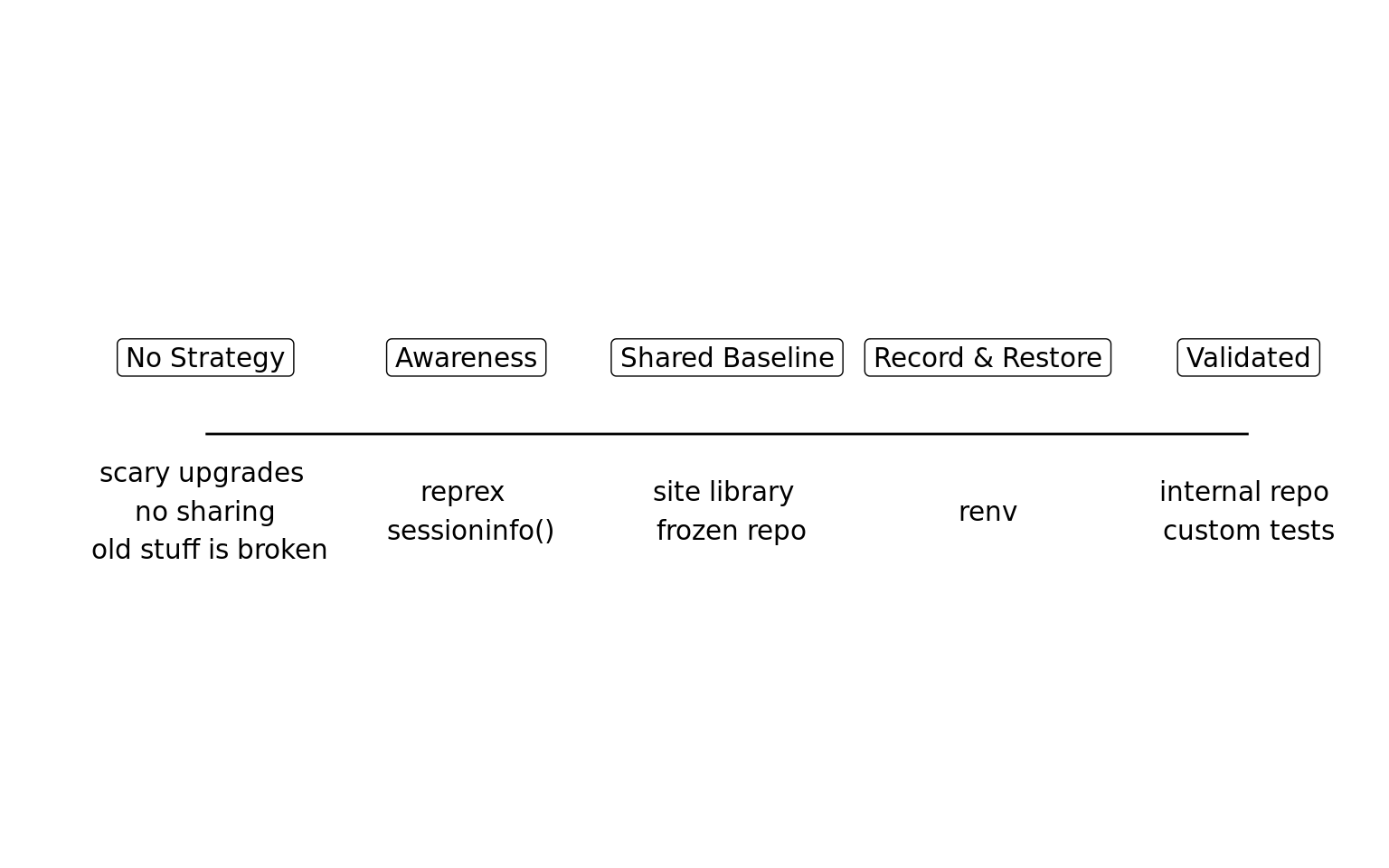
Strategies for reproducibility fall on a spectrum. One side is not better than the other. Pick based on your goals.
There are three main strategies covered in this site.
The Snapshot and Restore strategy is used when individual data scientists are responsible for managing a project and have full access to install packages. The strategy uses tools like renv1 to record a project’s dependencies and restore them.
The Shared Baseline strategy helps administrators coordinate the work of many data scientists by providing common sets of packages to use across projects. The key to this strategy is determining a consistent set of packages that work together.
The Validated strategy is used when packages must be controlled and meet specific organization standards.
The strategy map will help you pick between the different strategies.
Tools
Data science environments are built from a common set of tools.
If you use a shared server, some elements might be shared amongst projects and some elements might exist more than once; e.g. your server might have multiple versions of R installed. If your organization uses Docker containers, you might have a base image with some of these components, and runtime installation of others. Understanding these tools will help you create reproducible environments.
R Packages Managing and recording R packages makes up the bulk of this website. Specifically learn about repositories, installing packages, and managing libraries.
R Installation Packages like
renvwill normally document the version of R used by the project. On shared servers, it is common to install multiple versions of R. Organizations using Docker will typically include R in a base image. Learn more best practices for R installations.Other Languages Often data science projects are multi-lingual. Combining R and Python is the most common use case, and tools like
renvhave affordances for recording Python dependencies.System Dependencies R, Python, and their packages can depend on underlying software that needs to be installed on the system. For example, the
xml2R package depends on thelibxmlsystem package. Learn more about how system dependencies are documented and managed.Operating System Operating system configurations can be documented with tools like Docker or through Infrastructure-as-code solutions like Chef and Puppet. Often this step is managed outside of the data science team. Learn more about best practices for Docker.
Footnotes
renv is packrat 2.0↩︎