A Daily ETL process with R, Python, feather, Shiny, and secured credentials
Often applications require data that updates at a regular interval as the result of an ETL process. This example shows how to setup an R Markdown document that runs every day and uses Python to process Twitter data, and create a Shiny application that renders a dashboard that can automatically refresh when new data is available. Click here for the source code.
Scheduled ETL
Pull the latest batch of twitter data for the #rstats tag and performs some text cleansing. The R Markdown Notebook uses Python code to run daily updates on Connect.
The Shiny app
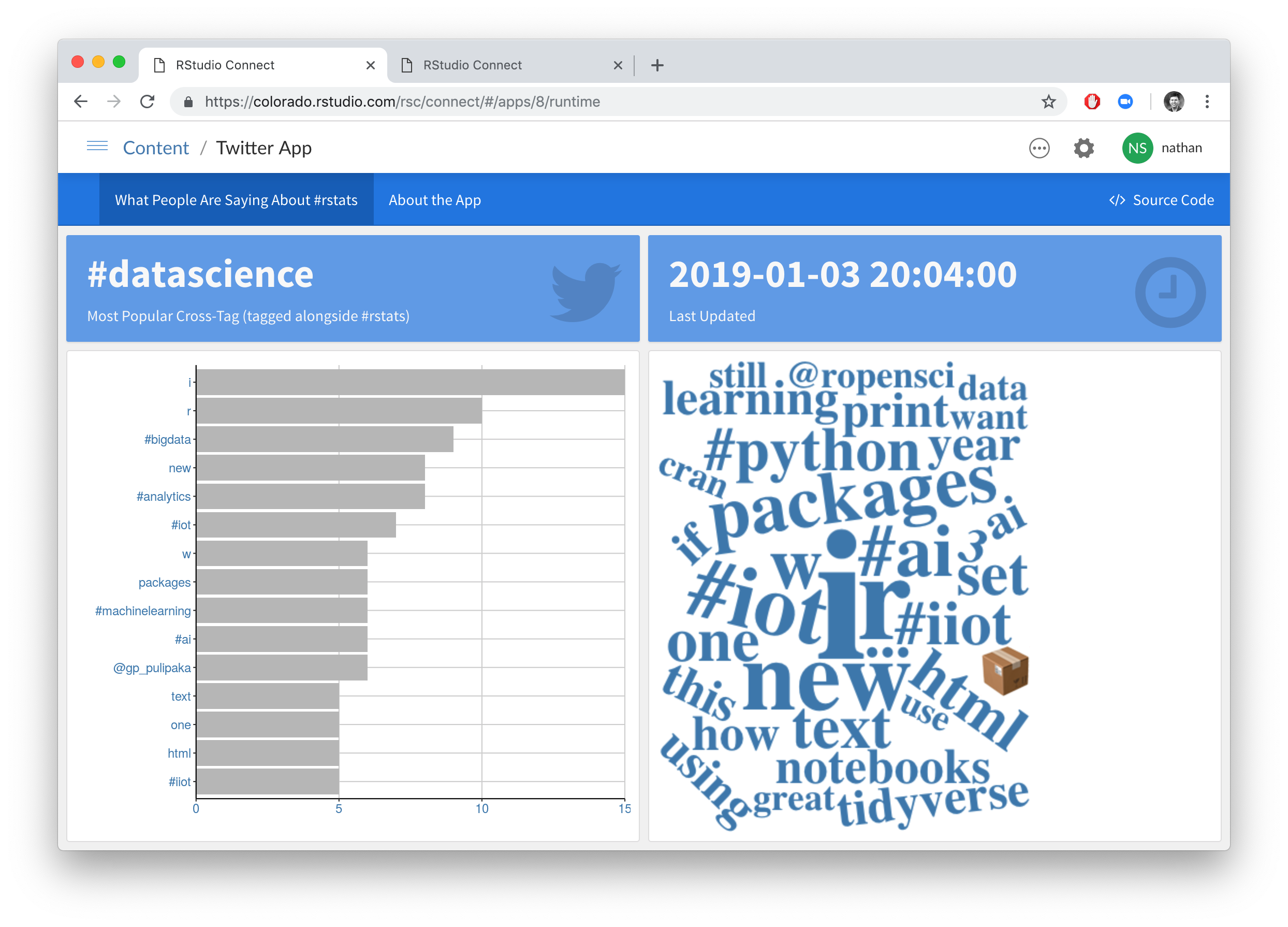
Visualize the text data produced by the ETL process. A Shiny application that is deployed and running on Connect.
Details
Why use Connect + R Markdown instead of crontab?
An alternative to using Connect would be to set up a crontab that runs the python script. The benefits of using Connect over this approach are:
The updates can be scheduled with a simple web UI
Connect will email you if a task fails and can optionally email you the html file (generated from the ETL Rmd file) as an artifact of success
Placing the ETL code in an Rmd file allows the code and documentation for the pipeline to live side-by-side
The Glue Holding Things Together
The Rmd file is using python to generate an aggregated, cleansed view of the data. This view is saved as a feather file. Feather is an optimized file format designed to be an intermediary between python and R. The downstream app uses reactivePoll to listen for changes to this file.
Additionally, the ETL Rmd updates a log file. This is done in an R code chunk with a system command. The log file is read in the app using a second reactiveFileReader.
Technical Pre-Reqs
The following python libraries must be installed on Connect:
pip install tweepy
pip install feather
pip install nltk
pip install pandasYou may also need to update the python feather package and the feather format:
pip install feather --upgrade
pip install feather-format --upgradeBe sure to have the latest version of the R feather package as well:
install.packages("feather")The nltk library requires a one-time download of the stopwords dataset:
import nltk
nltk.download('stopwords')The resulting feather file and log file need to be accessible by both the App and the Rmd file performing the data updates. To do so, a directory was created on Connect with read/write privileges for the rstudio-connect user. This directory was hard coded into both Rmd files prior to deploying the content.
A note on Twitter API Authentication
The twitter API requires credentials. These credentials were stored in a separate file that was read in the python ETL script. This file lives side-by-side with the python_etl_twitter.Rmd file and should be included in the deployment of the ETL Rmd. The credential file will end up living on the Connect server alongside the python_etl_twitter.Rmd file and will be readable by the rstudio-connect user.
To create this file:
Set up a twitter app: https://apps.twitter.com/
Create a feather file that contains the credentials in a dataframe:
library(feather) cred <- data.frame( consumer_key = CONSUMER_KEY, consumer_secret = CONSUMER_SECRET, access_token = ACCESS_TOKEN, access_token_key = ACCESS_TOKEN_SECRET ) write_feather(cred, "cred.feather")
Be sure to publish this file alongside of the python_etl_twitter.Rmd