Machine Learning Operations (MLOps) with vetiver and Posit
Overview
Machine learning operations, or MLOps, are a set of practices to deploy and maintain machine learning models in production reliably and efficiently. The vetiver framework is built for R and Python model workflows, giving you tools for model deployment, monitoring, and management. Using vetiver along with Posit professional products provides a sound strategy for Model Management in enterprise settings.
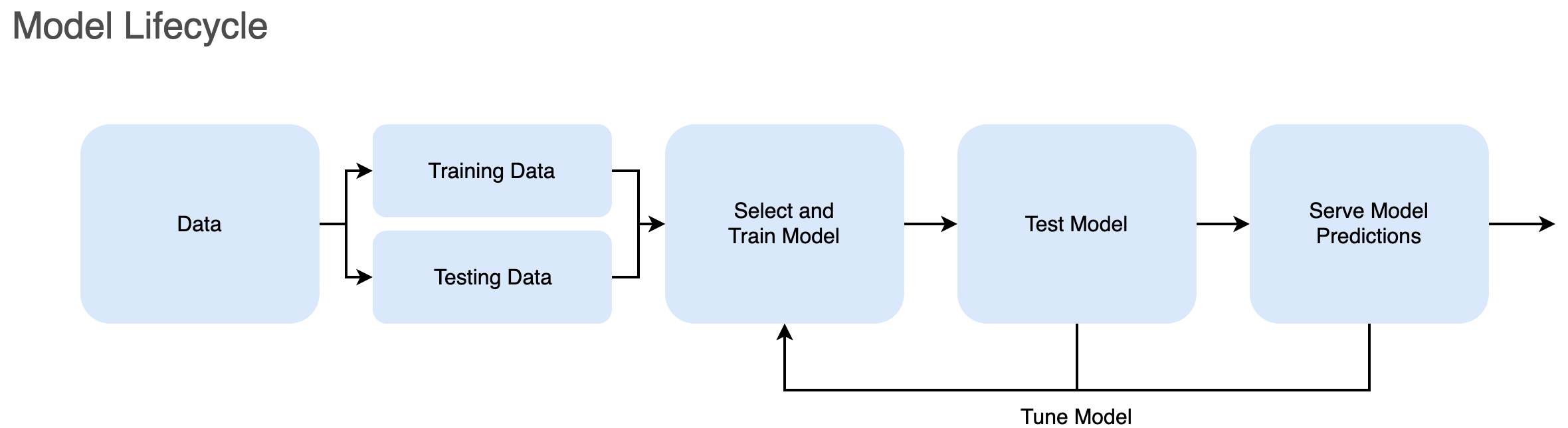
Different components of a model deployment pipeline can be developed using vetiver and Posit professional products:
- Train a model and produce different versions based on a schedule
- Deploy multiple versions of a model as REST API endpoints
- Retain a history of model versions for traceability
- Interact with model outputs in production for verification/consumption
Workbench can be used with machine learning packages (tidymodels in R or scikit-learn in Python) to develop, train, and score models during development. Connect can be used to deploy models as REST APIs, retrain models on a schedule and host model cards.
Training and deploying a Model
You can train a model in a Quarto document, R Markdown, or Jupyter Notebook and retain all of the information used to develop the trained model by publishing it on Connect for reproducibility and traceability.
In this example, the model training module uses an existing modelling package from R/Python to build a machine learning model which predicts number of bikes for each station. Once the model is finalized, it is converted into a vetiver model. This new vetiver model is then deployed on Connect as a pin so that we can operationalize the model training process and track different model versions based on changing input data.
View on Connect:
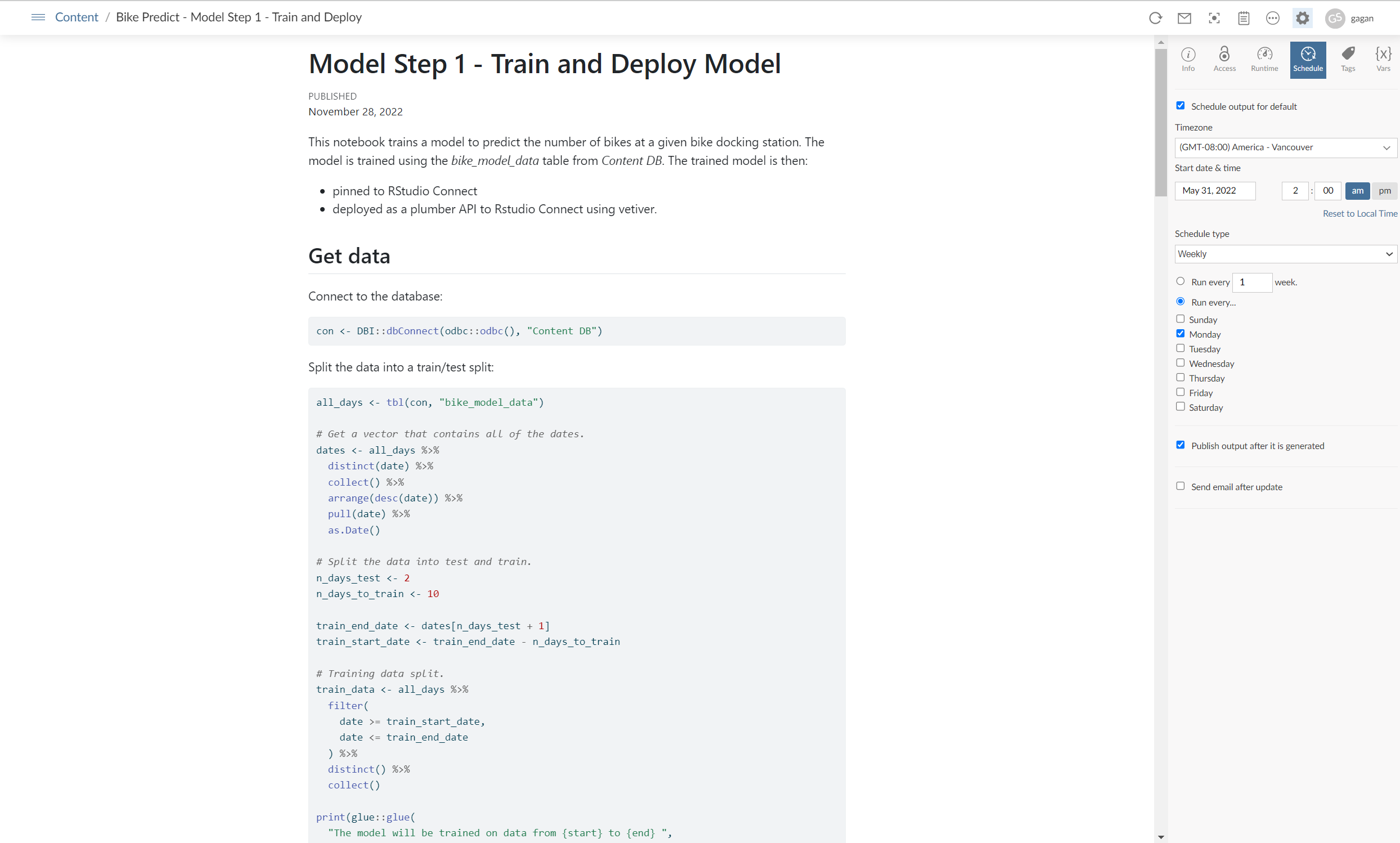
Since the input data source is constantly updated, this training and deployment module is rerun on a daily basis using Connect’s scheduling feature. This leads to new predictions each time and the latest version of the model is saved in the erstwhile mentioned pin.
Serving Model Predictions
Once the model is trained and deployed, we need to share the predictions with other applications. For this purpose, we use the vetiver framework to convert it to a REST API endpoint (plumber in R or fastapi in Python). No prior experience in creating APIs is needed; vetiver does this work for us. This model API is then deployed on Connect.
View on Connect:
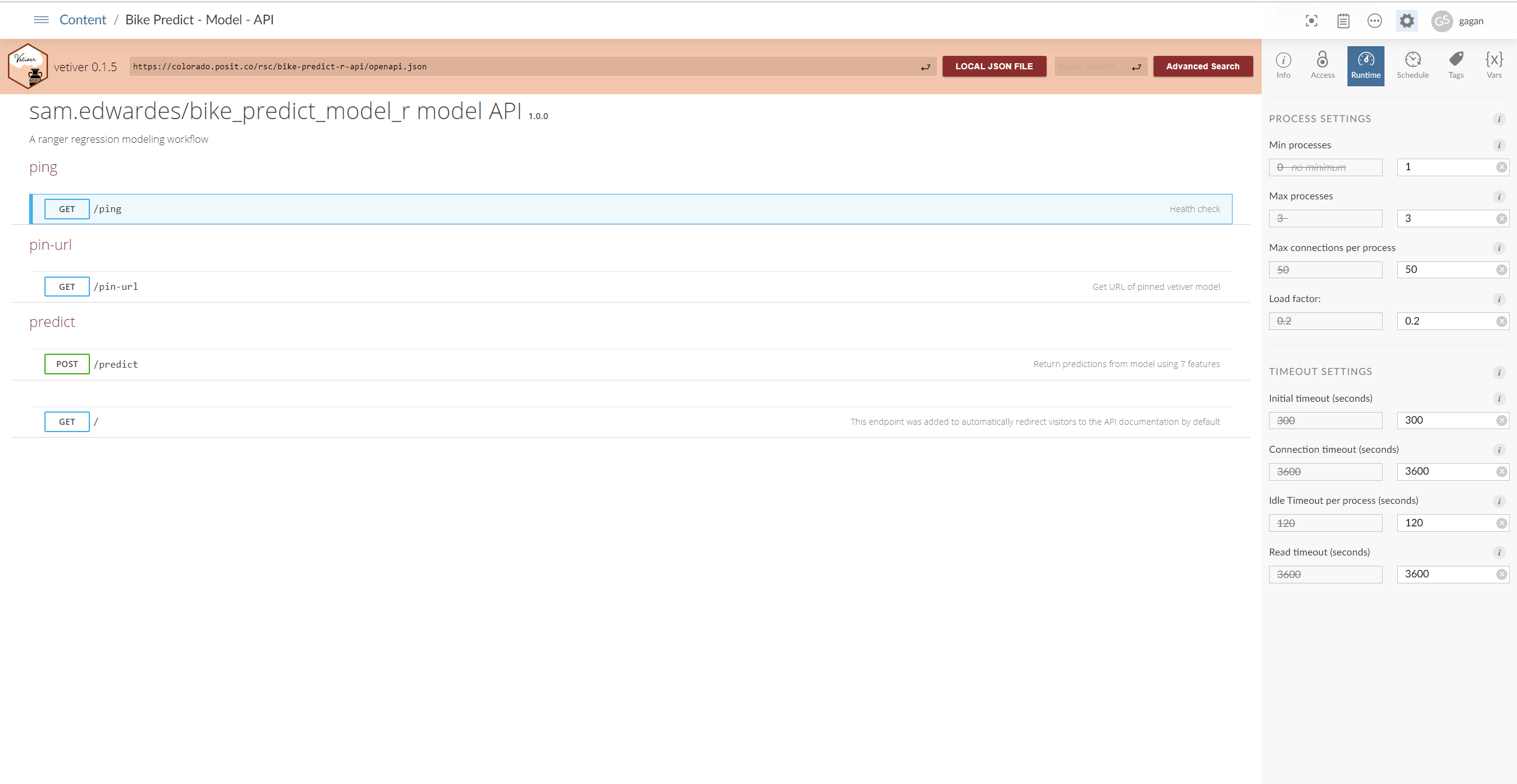
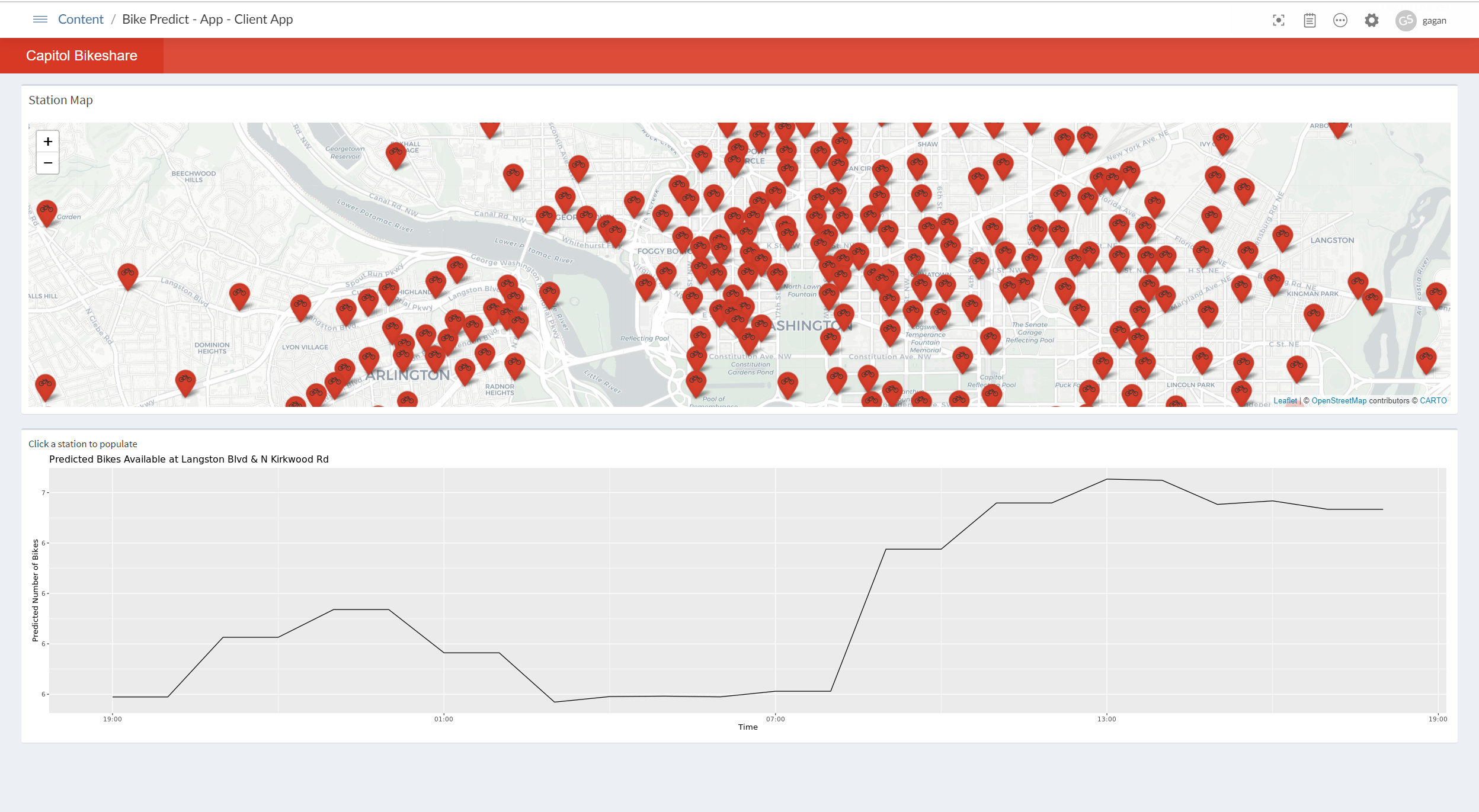
We can then use the custom URL feature in Connect to give the API a unique URL, which acts as an alias so that references to the model from other content will be stable even if the model is redeployed. For our case, we reference the model in a Shiny dashboard to visualize the predictions.
View on Connect:
Model monitoring
Model deployment is done on a schedule which produces a new version of the model. In order to make sure that this new version is performing well, this example has a monitoring module. It uses vetiver’s monitoring functions to track key performance metrics like RMSE and MAE. These metrics are also stored for further evaluation, like evaluating model drift.
This module is also deployed on Connect and matches the schedule of model training.
View on Connect:
Building a Model Card
A model card provides documentation on different aspects of a published machine learning model, like intended use, author details, evaluation metrics, etc. This examples utilizes vetiver’s model card function to generate a model card which is published on Connect.
Advanced modelling framework
The purpose of this example is to demonstrate how model management and various stages of the model lifecycle can be mapped to functionality in Posit Connect using the vetiver framework. This example is simplified and can be used as a starting point for advanced model pipelines as well.
One such extension can be building a A/B Testing framework to make sure the model in production is performing well. To implement this framework:
Train different model versions in development environment, and then deploy them as separate API’s using
vetiveron Connect.Monitor each model, and evaluate which model is performing the best under a pre-defined criteria.
Promote the best performing model to the production environment and share the consistent Connect custom URL for the
vetivermodel API with other applications.