8. Scaling
In this section, you will learn:
- How to effectively plan for scaling
- About different architecture options
Planning to scale
At some point, you may find that your team’s resource usage outgrows your initial Posit Connect implementation, and you may start to think about how to scale your Posit Connect server. Many options are available to scale out Connect, including setting up a load-balanced cluster or using Kubernetes for off-host execution.
The right architecture for scaling is dependent on your team and use case. Before you can decide on the right architecture you must understand how your team uses Connect. Below we’ll cover some of the factors about your team’s usage you need to understand.
How many users are accessing content concurrently?
The number of users concurrently accessing content is one of the principal determinants of “load.” For example, if ten users have access to Connect, but only one is using an application at any given time, your load is one. Knowing the average number of concurrent users, the peak, and how regularly it occurs helps to determine the load. You may also want to consider what platform adoption has looked like in the past to budget resources for expected growth.
Because the default is for R and Python to use a single thread - if users are not explicitly parallelizing their code, then you can estimate that your environment will need one core per concurrent process.
What type of content?
Reports
Reports are executed when published and when scheduled. The execution of these reports does use CPU and RAM; however, after they have run, they are inexpensive to serve up to users.
Applications and APIs
Applications and APIs run on one or more processes. As a new process is started, the resources required to run that application doubles. If users use large datasets in memory, you will need to allocate RAM accordingly, multiplied by the number of expected processes.
Applications tend to allow users to interactively work with in-memory data and are, therefore, often the largest consumer of RAM on the server. APIs tend to be more focused on a specific task and, therefore lighter weight in terms of their RAM footprint.
The requirements of large data sets can be potentially reduced if users can offload some work to a database or other processing tools such as spark.
While content running R and Python is single-threaded by default, in theory, any program could be written to leverage multi-threading depending on the developer’s packages, code, and skill. It is important to confirm if users are parallelizing their code as this can significantly change the estimate of CPU needs.
How established are workflows?
If your users’ workflows are long-established and very stable, then you may have high confidence in your resource usage expectations. However, if the team is newer or evolving the type of content they publish and consume, there may be more uncertainty, and you may want to add more of a buffer.
The answer to this question can also estimate how frequently system dependencies need to be managed. The OS system dependency requirements of a team with a long-established workflow may be more stable and require less management - something we’ll consider when we look at architecture options.
What is the expectation of uptime?
This will affect the buffer that you build in. It can also determine whether segregating into several nodes is preferable (i.e. if a piece of content can occupy all the resources on a given machine, other content can still utilize another machine).
Collect this information for your team:
- How many content publishers do you have?
- How many content consumers do you have?
- What type of content will be published?
- How many processes do you expect to be running concurrently per piece of content?
- What do you expect the load to be on average and at peak?
- Do you have historical usage metrics you can review from users?
Connect Architectures
When you have a clear picture of your team’s use case and needs, you can start evaluating the best architecture for your team’s Connect deployment.
A single Posit Connect server is how many teams get started. This architecture is the simplest, without any requirements of external shared storage. If you do not require high availability - just increasing the server size of a single Connect server and scaling vertically can be a great scaling strategy!
Below we show a decision tree that provides a starting framework for thinking about which architecture best fits your needs. Your organization likely has additional criteria that are critical to making this decision. For example, you may have specific software deployment patterns that you need to follow, like always deploying apps in a container.
We recommend selecting the most straightforward architecture that meets your current and near-term needs, then growing the complexity and scale as needed.

Connect cluster
A Posit Connect cluster has at least 2 Connect nodes (servers), a shared file storage, a shared PostgreSQL database, and a load balancer. Below is an example of a two-node Connect cluster:
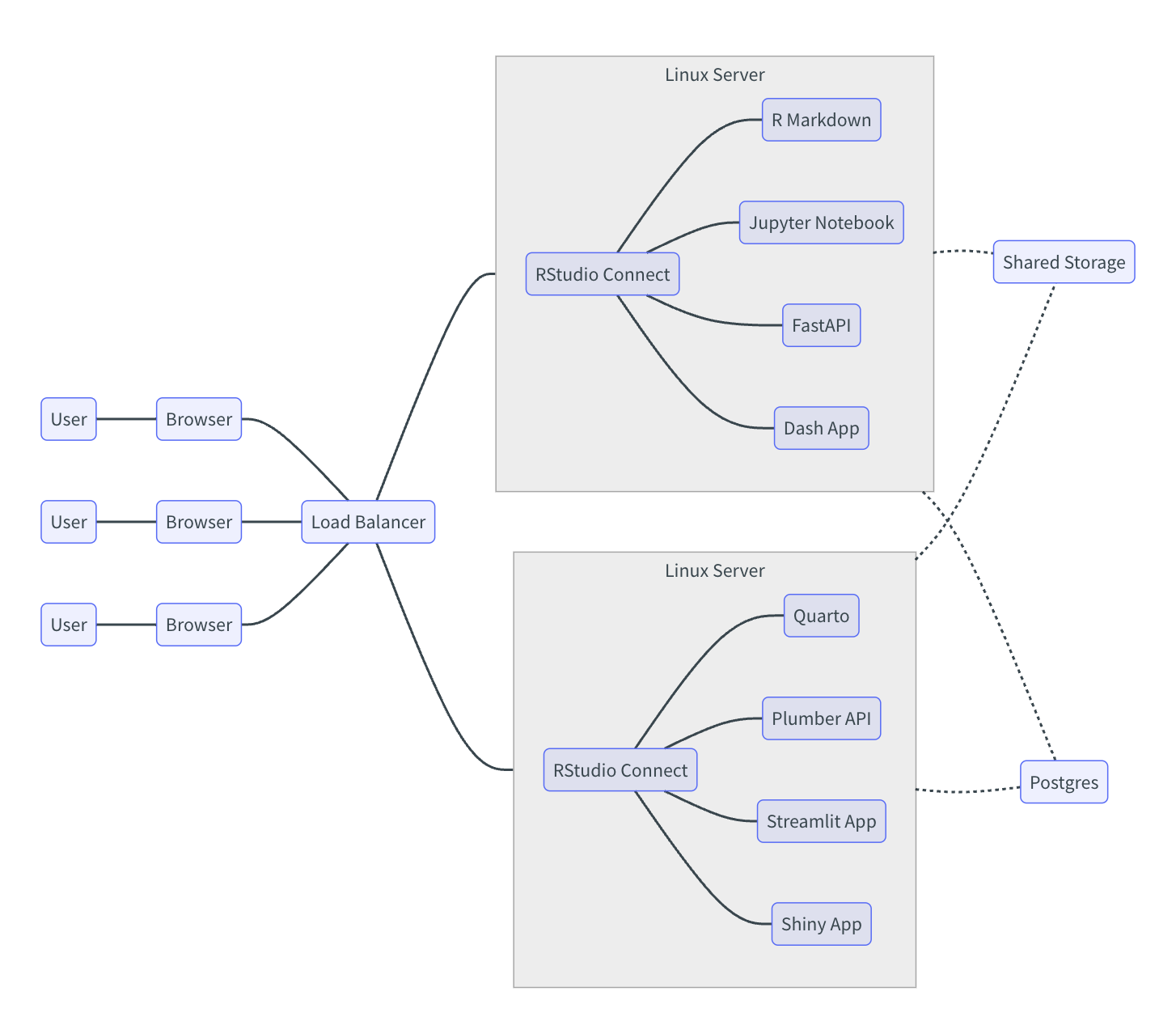
In the diagram, a user uses their browser, and the load balancer distributes new sessions between the two nodes. The load balancer needs to have sticky session enabled.
A cluster setup provides both a highly available setup and a load-balanced setup where content can be run on different servers.
Connect with off-host execution (Kubernetes)
Posit Connects has support for a remote execution model in which environments are built, and content is executed in containers using Kubernetes. This architecture requires an external shared file server and a PostgreSQL database that are accessible to the pods running content and the Connect service pods. The diagram below provides an example of this architecture:
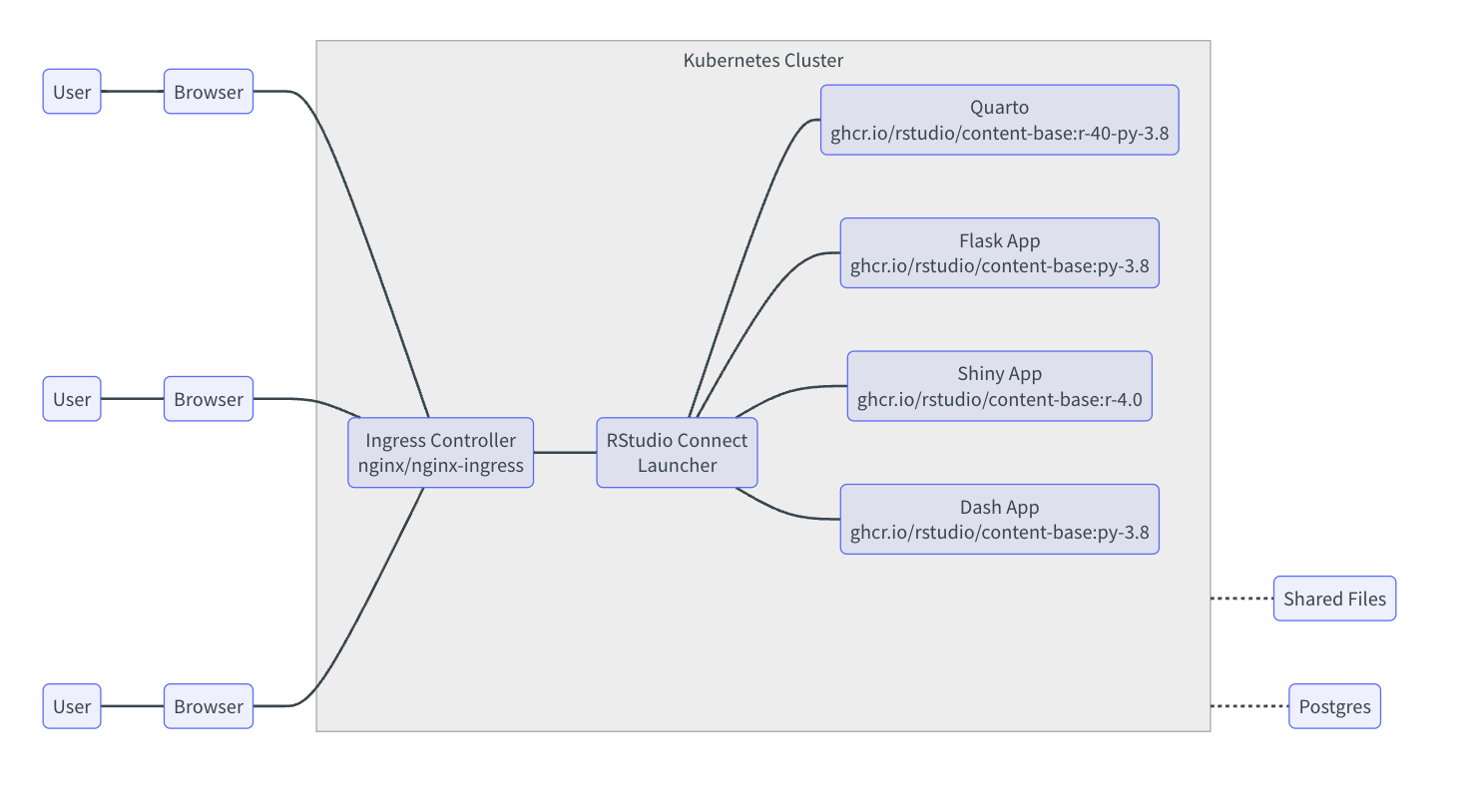
Posit Connect is recommended to be installed in a Kubernetes cluster using the Posit-maintained Helm chart. This enables:
- Multiple publishers and viewers to access Posit Connect via a web browser
- Replica redundancy for multiple instances of the Connect service Pods
- Execution of R, Python, and Quarto content in an isolated Kubernetes container external to Connect (instead of a local process)
- Admins to define and customize the set of base images available for creating content build and execution containers
- Publishers to target a specific base image for their content or allow Connect to choose the best fit by comparing the available runtime version components
Exercise
Outline the pros and cons of each architecture option
Using what you know about your team and its use case, consider the pros and cons of each configuration; which one do you think fits your team’s needs currently? How about if your team doubles in size?
Go to: 9. Troubleshooting